 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixIE: Prompted Pixel-Space Low-Light Image Enhancement
May 27, 2026Low-light images suffer from severe noise, contrast loss, and semantic ambiguity, making enhancement a joint problem of denoising and detail recovery. We propose PixIE, a feed-forward pixel-space LLIE framework semantically prompted by a vision foundation model. PixIE first performs cross-scale denoising to suppress noise and preserve structure, then refines details using DINO-Prompted Pixel Blocks (DPPBs), which inject intermediate DINOv3 features through patch-conditioned, spatially continuous per-pixel modulation. To make pixel-space attention efficient across scales, we introduce Spatial-Channel Compaction (SCC), which jointly reduces the spatial token grid and channel dimension. We further propose Multi-Receptive-Field Pixel Embedding (MRPE) to provide neighborhood-aware pixel representations before semantic prompting, improving robustness to signal-dependent noise beyond point-wise embeddings. Experiments on LLIE benchmarks show that PixIE improves average PSNR by 1.9-15.0% over recent state-of-the-art methods and reduces LPIPS by 8.5-44.4%. Qualitative comparisons further show sharper details and more stable textures, improving both reconstruction fidelity and perceptual quality.
BVI-Mamba: Video Enhancement Using a Visual State-Space Model for Low-Light and Underwater Environments
Apr 26, 2026Videos captured in low-light and underwater conditions often suffer from distortions such as noise, low contrast, color imbalance, and blur. These issues not only limit visibility but also degrade automatic tasks like detection. Post-processing is typically required but can be time-consuming. AI-based tools for video enhancement also demand significantly more computational resources compared to image-based methods. This paper introduces a novel framework, Visual Mamba, designed to reduce memory usage and computational time by leveraging the Visual State Space (VSS) model. The framework consists of two modules: (i) a feature alignment module, where spatio-temporal displacement between input frames is registered in the feature space, and (ii) an enhancement module, where noise removal and brightness adjustment are performed using a UNet-like architecture, with all convolutional layers replaced by VSS blocks. Experimental results show that the Visual Mamba technique outperforms Transformer and convolution-based models in both low-light and underwater video enhancement tasks. Code is available on line at https://github.com/russellllaputa/BVI-Mamba.
Identity-Consistent Video Generation under Large Facial-Angle Variations
Mar 22, 2026Single-view reference-to-video methods often struggle to preserve identity consistency under large facial-angle variations. This limitation naturally motivates the incorporation of multi-view facial references. However, simply introducing additional reference images exacerbates the \textit{copy-paste} problem, particularly the \textbf{\textit{view-dependent copy-paste}} artifact, which reduces facial motion naturalness. Although cross-paired data can alleviate this issue, collecting such data is costly. To balance the consistency and naturalness, we propose $\mathrm{Mv}^2\mathrm{ID}$, a multi-view conditioned framework under in-paired supervision. We introduce a region-masking training strategy to prevent shortcut learning and extract essential identity features by encouraging the model to aggregate complementary identity cues across views. In addition, we design a reference decoupled-RoPE mechanism that assigns distinct positional encoding to video and conditioning tokens for better modeling of their heterogeneous properties. Furthermore, we construct a large-scale dataset with diverse facial-angle variations and propose dedicated evaluation metrics for identity consistency and motion naturalness. Extensive experiments demonstrate that our method significantly improves identity consistency while maintaining motion naturalness, outperforming existing approaches trained with cross-paired data.
Prune Wisely, Reconstruct Sharply: Compact 3D Gaussian Splatting via Adaptive Pruning and Difference-of-Gaussian Primitives
Feb 27, 2026Recent significant advances in 3D scene representation have been driven by 3D Gaussian Splatting (3DGS), which has enabled real-time rendering with photorealistic quality. 3DGS often requires a large number of primitives to achieve high fidelity, leading to redundant representations and high resource consumption, thereby limiting its scalability for complex or large-scale scenes. Consequently, effective pruning strategies and more expressive primitives that can reduce redundancy while preserving visual quality are crucial for practical deployment. We propose an efficient, integrated reconstruction-aware pruning strategy that adaptively determines pruning timing and refining intervals based on reconstruction quality, thus reducing model size while enhancing rendering quality. Moreover, we introduce a 3D Difference-of-Gaussians primitive that jointly models both positive and negative densities in a single primitive, improving the expressiveness of Gaussians under compact configurations. Our method significantly improves model compactness, achieving up to 90\% reduction in Gaussian-count while delivering visual quality that is similar to, or in some cases better than, that produced by state-of-the-art methods. Code will be made publicly available.
Dynamic Weight-based Temporal Aggregation for Low-light Video Enhancement
Oct 10, 2025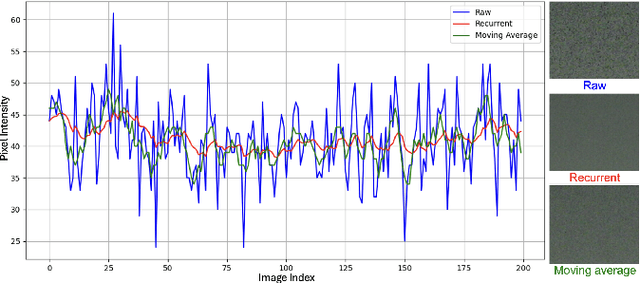
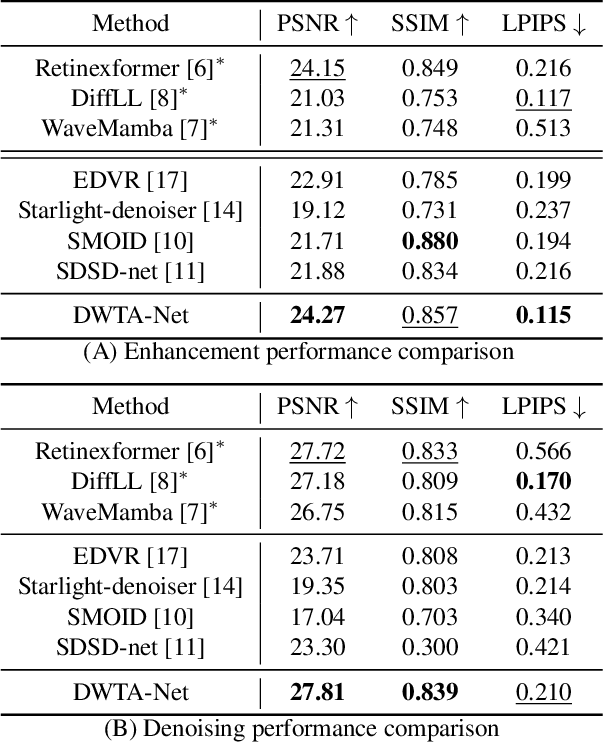


Low-light video enhancement (LLVE) is challenging due to noise, low contrast, and color degradations. Learning-based approaches offer fast inference but still struggle with heavy noise in real low-light scenes, primarily due to limitations in effectively leveraging temporal information. In this paper, we address this issue with DWTA-Net, a novel two-stage framework that jointly exploits short- and long-term temporal cues. Stage I employs Visual State-Space blocks for multi-frame alignment, recovering brightness, color, and structure with local consistency. Stage II introduces a recurrent refinement module with dynamic weight-based temporal aggregation guided by optical flow, adaptively balancing static and dynamic regions. A texture-adaptive loss further preserves fine details while promoting smoothness in flat areas. Experiments on real-world low-light videos show that DWTA-Net effectively suppresses noise and artifacts, delivering superior visual quality compared with state-of-the-art methods.
RUSplatting: Robust 3D Gaussian Splatting for Sparse-View Underwater Scene Reconstruction
May 21, 2025Reconstructing high-fidelity underwater scenes remains a challenging task due to light absorption, scattering, and limited visibility inherent in aquatic environments. This paper presents an enhanced Gaussian Splatting-based framework that improves both the visual quality and geometric accuracy of deep underwater rendering. We propose decoupled learning for RGB channels, guided by the physics of underwater attenuation, to enable more accurate colour restoration. To address sparse-view limitations and improve view consistency, we introduce a frame interpolation strategy with a novel adaptive weighting scheme. Additionally, we introduce a new loss function aimed at reducing noise while preserving edges, which is essential for deep-sea content. We also release a newly collected dataset, Submerged3D, captured specifically in deep-sea environments. Experimental results demonstrate that our framework consistently outperforms state-of-the-art methods with PSNR gains up to 1.90dB, delivering superior perceptual quality and robustness, and offering promising directions for marine robotics and underwater visual analytics.
Visual enhancement and 3D representation for underwater scenes: a review
May 03, 2025
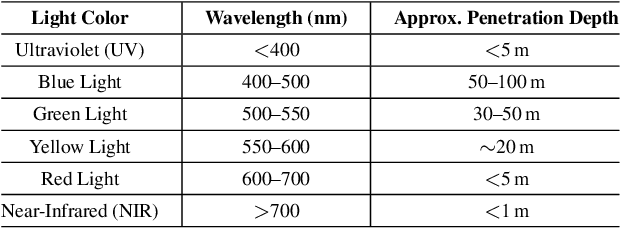


Underwater visual enhancement (UVE) and underwater 3D reconstruction pose significant challenges in computer vision and AI-based tasks due to complex imaging conditions in aquatic environments. Despite the development of numerous enhancement algorithms, a comprehensive and systematic review covering both UVE and underwater 3D reconstruction remains absent. To advance research in these areas, we present an in-depth review from multiple perspectives. First, we introduce the fundamental physical models, highlighting the peculiarities that challenge conventional techniques. We survey advanced methods for visual enhancement and 3D reconstruction specifically designed for underwater scenarios. The paper assesses various approaches from non-learning methods to advanced data-driven techniques, including Neural Radiance Fields and 3D Gaussian Splatting, discussing their effectiveness in handling underwater distortions. Finally, we conduct both quantitative and qualitative evaluations of state-of-the-art UVE and underwater 3D reconstruction algorithms across multiple benchmark datasets. Finally, we highlight key research directions for future advancements in underwater vision.
Marine Snow Removal Using Internally Generated Pseudo Ground Truth
Apr 27, 2025



Underwater videos often suffer from degraded quality due to light absorption, scattering, and various noise sources. Among these, marine snow, which is suspended organic particles appearing as bright spots or noise, significantly impacts machine vision tasks, particularly those involving feature matching. Existing methods for removing marine snow are ineffective due to the lack of paired training data. To address this challenge, this paper proposes a novel enhancement framework that introduces a new approach for generating paired datasets from raw underwater videos. The resulting dataset consists of paired images of generated snowy and snow, free underwater videos, enabling supervised training for video enhancement. We describe the dataset creation process, highlight its key characteristics, and demonstrate its effectiveness in enhancing underwater image restoration in the absence of ground truth.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Bayesian Neural Networks for One-to-Many Mapping in Image Enhancement
Jan 24, 2025



In image enhancement tasks, such as low-light and underwater image enhancement, a degraded image can correspond to multiple plausible target images due to dynamic photography conditions, such as variations in illumination. This naturally results in a one-to-many mapping challenge. To address this, we propose a Bayesian Enhancement Model (BEM) that incorporates Bayesian Neural Networks (BNNs) to capture data uncertainty and produce diverse outputs. To achieve real-time inference, we introduce a two-stage approach: Stage I employs a BNN to model the one-to-many mappings in the low-dimensional space, while Stage II refines fine-grained image details using a Deterministic Neural Network (DNN). To accelerate BNN training and convergence, we introduce a dynamic \emph{Momentum Prior}. Extensive experiments on multiple low-light and underwater image enhancement benchmarks demonstrate the superiority of our method over deterministic models.